Building a Retrieval-Augmented Text Classifier#
Retrieval-Augmented Classification (RAC) is a technique that enables building classifiers that can adapt to new information without retraining and maintaining their performance even as things change. This is achieved by training models to look up external data (referred to as memories) to guide their outputs.
In this tutorial we will build a simple retrieval-augmented sentiment classifier for the Twitter US Airline Sentiment dataset. The tutorial assumes basic knowledge of Python.
OrcaLib provides a simple framework for building retrieval-augmented models which makes it really easy to get a model up and running with Orca and fine-tune it to your needs in a few lines of code.
How do I use Orca with my custom model architecture?
While our modeling framework simplifies getting started, Orca memorysets can be used to inject memories into any PyTorch model. OrcaLib contains specialized PyTorch layers that facilitate adding retrieval-augmentation to your custom model architecture. Get in touch if you are interested in adding retrieval-augmentation to your custom model.
This will tutorial will demonstrate the basic steps for building a retrieval augmented model with Orca. There are additional steps you will want to follow to tweak your model to achieve state of the art performance, but this tutorial will get you started to:
- Loading and processing the dataset
- Setting up our
LabeledMemoryset - Building a
RACModel - Finetuning the model and evaluating it
- Inspecting memories accessed at inference
Load the Dataset#
For this tutorial, we will just need to install the OrcaLib and Datasets dependencies. You can do this using your preferred package manager:
With that out of the way, let’s load the Twitter US Airline Sentiment dataset from  Hugging Face. The dataset contains tweets about US airlines and their sentiment labels. Our model will take tweet texts as inputs and output a predicted sentiment label.
Hugging Face. The dataset contains tweets about US airlines and their sentiment labels. Our model will take tweet texts as inputs and output a predicted sentiment label.
Let’s go ahead and load the dataset into a Dataset object. We also need to clean up the dataset a little before we can work with it:
- This dataset only contains a single split, so we select it here.
- Each row in this dataset was independently labeled by multiple annotators. To ensure high quality labels, we only keep rows where all annotators agree on the label.
- There are a lot of features in this dataset that we don’t need, so we select only the ones we need.
- The
airline_sentimentfeature of this dataset is not configured as a proper ClassLabel feature, so we convert it to one. This will make it easier to ingest the dataset into OrcaDB as an EnumT column. - We create a standard 80%/20% train/test split of the dataset.
Now we have a training set with 8356 rows and a test set with 2089 rows with two features:
textcontains the tweet text.labelcontains the sentiment of the tweet, which can be:- negative (~70.7% of the dataset)
- neutral (~14.8% of the dataset)
- positive (~14.5% of the dataset)
Create a Memoryset#
What should we use for memories? For a RAC model, we want to store examples of inputs and outputs that are similar to the inputs we want the model to classify. So in our case, we want to store examples of tweets that are similar to the ones we want the model to classify and their corresponding sentiment labels. At inference time, the model will look up memories similar to the input to guide its outputs.
We find memories similar to a given input by generating embeddings for the memories and then comparing them to the input’s embedding. Orca provides a convenient way to store memories with labels, generate embeddings, and look up relevant memories for a given input using the LabeledMemoryset class.
Memorysets are stored in an OrcaDB table. OrcaDBs are usually hosted in our cloud, but we also support experimental local file-based OrcaDBs for development and testing.
Let’s create a LabeledMemoryset for storing our memories. We will store the memories in a local OrcaDB file called local.db and create a table called airline_sentiment in that database.
- We use a file URL with a fragment to specify the local database and table name here.
- We use Alibaba’s GTE v1.5 base embedding model to generate embeddings for the memories. This is a powerful and fast embedding model that is suitable for a wide variety tasks.
Follow the steps in the Deployment Guide to deploy your OrcaDB and store it in an environment variable.
Now we can create a LabeledMemoryset for storing our memories. We will use the database URL stored in the ORCADB_URL environment variable to connect to our database and store the memories in a table called airline_sentiment.
- We get the database URL from the
ORCADB_URLenvironment variable to ensure it is not hard-coded in the codebase. See the Deployment Guide to learn where to get your database URL and how to load it into an environment variable. - We use Alibaba’s GTE v1.5 base embedding model to generate embeddings for the memories. This is a powerful and fast embedding model that is suitable for a wide variety tasks.
We will get started by using our training data as memories. To optimize performance and steerability, you might want to curate your memories to only contain the most relevant examples, or even add synthetic examples.
To insert the training data into our memoryset, we use the insert method. Embeddings will automatically be generated by the memoryset and stored alongside the data.
- When inserting a
Datasetinto aLabeledMemoryset, the dataset must have atextorvaluefeature and alabelfeature. Insert supports a wide variety of data structures, see the Memoryset Guide for more details.
You can inspect the first 5 rows of the memoryset represented as a DataFrame by calling the memoryset.df(5).
Create a RAC Model#
The easiest way to create a retrieval-augmented classifier is to use the RACModel class. This class automates the retrieval of memories similar to the given input from the memoryset and the generation of embeddings of the inputs with the memoryset’s embedding model. It then uses a classification head that takes in the input embeddings, memory embeddings, and memory labels to produces a final prediction.
- We specify the number of classes in the classification task, which is 3 (negative, neutral, positive) in our case. This is the only required argument for the
RACModelall other arguments have reasonable defaults. - We specify the classification head to use in the model. For this tutorial, we will use the default, which is a mixture of memory experts that implements a cross-attention mechanism between the input embeddings and memory embeddings using the memory labels to output logits for the label classes.
- We attach the memoryset to look up memories from. You can easily attach a different memoryset by calling
model.attach(memoryset)at any point. - We specify the number of memories the model will retrieve and pass to the classification head.
The following diagram shows the data flow through the model and attached memoryset:


Because the RAC model grounds its predictions in the provided memories the MMOE head can be initialized to produce predictions that are useful out of the box without any finetuning. We can observe this by evaluating the model on the test dataset.
You should get a result that contains an accuracy score of around 85% out of the box without any finetuning. The evaluate method also calculates the loss, F1 score, and ROC AUC score.
Finetune the Model#
To improve the model’s performance, we can easily finetune it on the training data. For that we can simply call the finetune method on our model which will handle the whole process under the hood. (1)
- For more advanced training, you can also implement retrieval-augmented models from scratch using our custom PyTorch layers. See the Custom Modeling Guide to learn more.
This will finetune the model on the training data for 3 epochs and plot a loss curve.
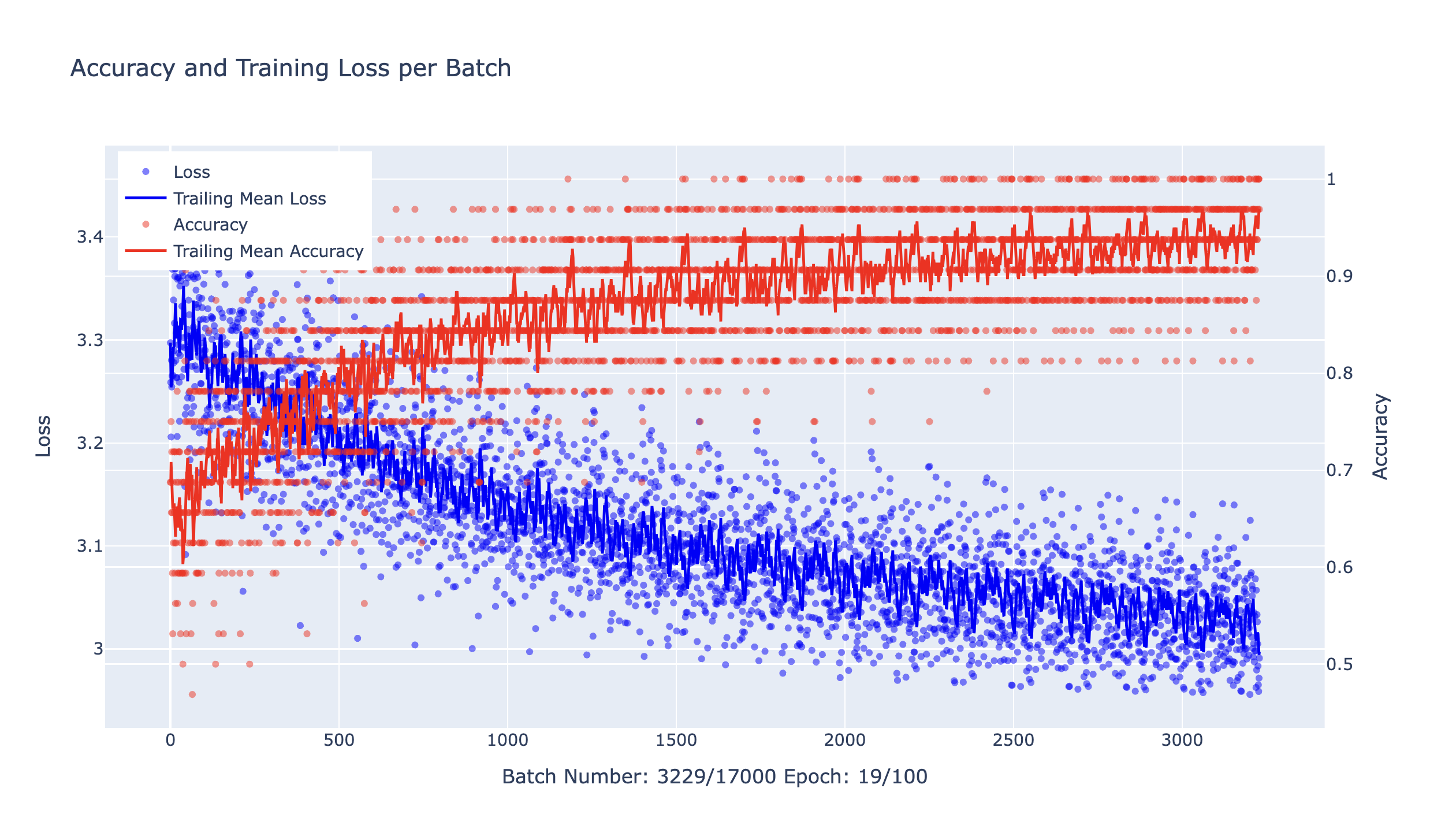
After finetuning our model, we can evaluate it again by passing the test dataset to the evaluate method.
The result should show an improvement in the accuracy score, indicating that the model is now able to make more accurate predictions on the test data.
Finally we might want to save the finetuned model to disk by calling the save method on the model. This way we can load it back up using the load method without having to retrain it.
Inspect Accessed Memories#
To inspect the memories accessed by the model during inference, we can use the explain method. This method returns a dictionary with the input data, the accessed memories, and additional information.
This will print a table with the memories that were accessed by the model during inference.
+-------+------------+--------------------+------------------+-------------------------------------------------------------------------------+-----------+
| label | label_name | lookup_score | attention_weight | memory_example | memory_id |
+-------+------------+--------------------+------------------+-------------------------------------------------------------------------------+-----------+
| 0 | None | 0.8553093592220293 | 0 | Since I couldn't find what I had before I find this one acceptable. | 410 |
| 0 | None | 0.8548836292574795 | 0 | it is everything i thought it would be and more. | 2138 |
| 0 | None | 0.8542388012923502 | 0 | There's enough going on in real life to write about without delving into ment | 3492 |
| 0 | None | 0.8541990522740802 | 0 | Just when I thought I had the whole thing figured out, it twisted and made me | 2481 |
+-------+------------+--------------------+------------------+-------------------------------------------------------------------------------+-----------+
The output shows the similar memories that the model retrieved for our input. In addition to the value and label of the memory, the table shows the lookup score and attention weights. The lookup score is the similarity metric used to identify the most similar memories during retrieval. The attention weight is the weight the model learned to assign to each memory in the cross attention mechanism of the MMOE head. These attention weights are used to combine the memories in the final prediction.
As we can see our RAC model can not only make accurate predictions but also adapt to new information without retraining, since its inferences are based on the memoryset. This allows us to update the models behavior by updating the memoryset without retraining.
Up Next#
To explore this further, check out our tutorial on how retrieval-augmented models can adapt to data drift by adding new memories without retraining. Alternatively, check out our guide on how to analyze your memoryset in more detail and learn how to tune the contents of your memoryset to improve model performance.